Point clé
Un test en deux questions sépare la documentation RS&DE IA qui survit à un audit de l'ARC de celle qui échoue : chaque affirmation technique peut-elle être retracée jusqu'à un artefact source, ou a-t-elle été générée à partir d'une invite?
Un directeur technique d’une entreprise SaaS de Toronto nous a posé cette question en avril : « Nous utilisons un outil d’IA pour la préparation des RS&DE. Comment expliquer à mon directeur financier s’il s’agit du type qui résistera à un audit ou non? »
C’est la bonne question. Il existe une réponse structurelle qui ne nécessite pas d’évaluer chaque fournisseur au cas par cas. Il existe un seul test qui distingue la documentation préparée par IA qui survit à une vérification de l’ARC de la documentation qui échoue. Le test est architectural, et la différence se voit dès le premier paragraphe du T661.
Cet article décrit le test, présente deux exemples concrets et montre ce que chaque architecture produit lorsque le processus de vérification de l’ARC se déroule réellement. Si vous envoyez ceci à votre directeur financier avant une conversation de validation, la deuxième moitié est ce qu’il doit lire. Le traitement approfondi de la façon dont les catégories fonctionnent se trouve dans notre guide sur les réclamations RS&DE préparées par IA.
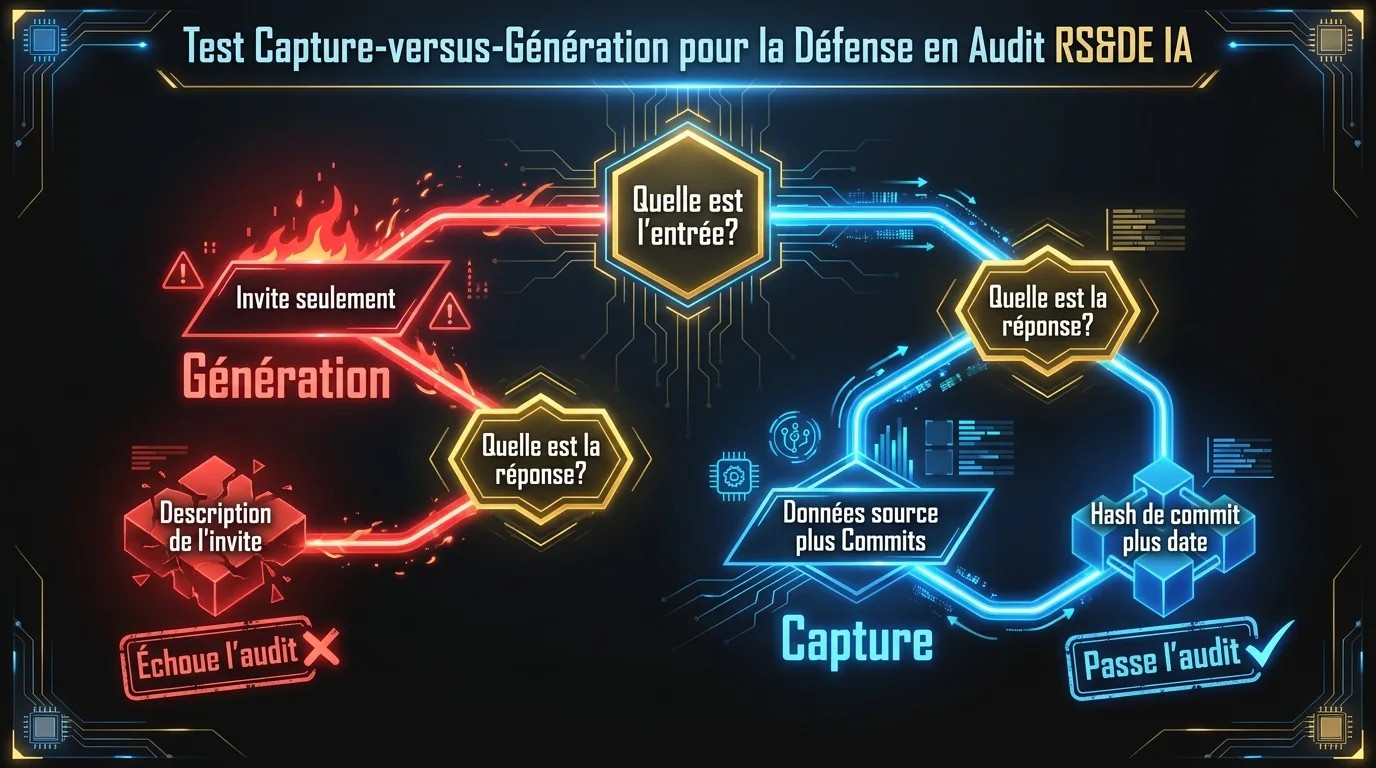
En quoi consiste le test capture contre génération?
Les outils d’IA pour la préparation des RS&DE se divisent sur un seul axe architectural : capture ou génération. Les deux approches produisent de la documentation avec des profils de vérification très différents. Les évaluateurs de l’ARC peuvent faire la différence, tout comme les outils de filtrage IA qui tournent maintenant sur les narratifs T661 entrants.
Le test comporte deux questions.
Première question : quelle est l’entrée du modèle de langage quand il produit le narratif?
Si l’entrée est une invite et un nom de projet, l’outil génère. Si l’entrée est de la preuve structurée tirée de vos données source réelles (historique git, pull requests, entrées du gestionnaire de tickets, messages Slack tagués), l’outil capture.
Deuxième question : quand l’ARC demande d’où provient une affirmation spécifique dans le narratif, quelle est la réponse?
Si la réponse est une description de l’invite, la documentation est de la génération. Si la réponse est un hash de commit spécifique, un numéro de pull request ou un identifiant de ticket avec une date, la documentation est de la capture.
Les deux questions sont la même question formulée dans deux directions. La génération est une reconstruction au moment de la déclaration. La capture est une documentation contemporaine liée à des artefacts source. Le standard de vérification 2026 de l’ARC, ancré dans le nouveau programme d’approbation préalable aux réclamations, a été construit autour de la deuxième catégorie et non de la première.
Pourquoi ce test est-il important en 2026?
L’ARC a lancé l’approbation préalable aux réclamations le 1er avril 2026. Le programme permet à un demandeur de soumettre un projet planifié pour confirmation d’admissibilité avant de produire une déclaration. La contrepartie est que la soumission doit inclure de la documentation contemporaine, définie dans les propres documents de l’ARC comme des dossiers créés pendant le travail lui-même, pas reconstitués au moment de la déclaration.
L’exigence de preuve contemporaine est le changement substantiel. Pendant la majeure partie de l’histoire du programme, les narratifs techniques étaient produits au moment de la déclaration, parfois des mois après le travail sous-jacent. Les narratifs décrivaient le travail avec suffisamment de précision pour la déclaration. Ils n’étaient pas, selon la définition 2026 de l’ARC, contemporains. Le nouveau programme n’accepte pas la reconstruction. Un outil d’IA basé sur la génération produit de la prose au moment de la déclaration par définition. Un outil d’IA basé sur la capture produit de la documentation contemporaine par défaut, parce qu’il documente le travail au fur et à mesure qu’il se déroule.
L’ARC utilise aussi l’IA du côté de la vérification. Le Plan ministériel 2025-26 décrit l’agence « améliorant son utilisation de la technologie, notamment l’apprentissage automatique et l’intelligence artificielle, pour détecter la non-conformité et d’autres activités suspectes. » Pour les évaluateurs RS&DE, cela signifie qu’un écran d’IA tourne maintenant sur les narratifs T661 entrants et signale les schémas associés à une documentation de mauvaise qualité ou fabriquée.
La Cour canadienne de l’impôt a renforcé l’attente de documentation contemporaine dans DAZZM Inc. c. Le Roi, 2024 CCI 129, où la cour a refusé une réclamation RS&DE en partie parce que la documentation soumise lors de la révision avait été substantiellement reconstituée après coup.
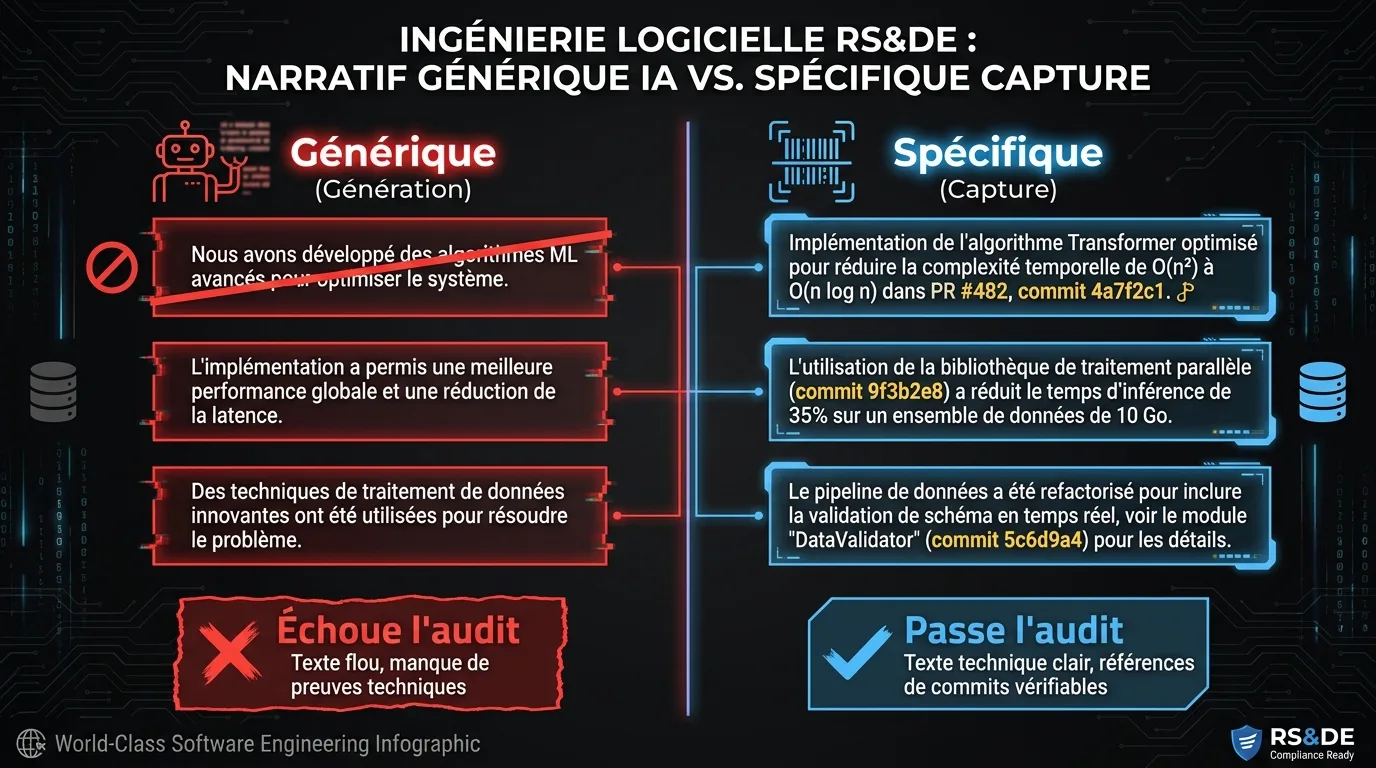
Exemple 1 : la génération en pratique
Une entreprise logicielle de taille intermédiaire à Vancouver soumet une réclamation RS&DE via un outil d’IA basé sur la génération. L’outil ingère une brève description de projet fournie par le directeur technique et une liste de noms de projets du responsable technique. Il produit un narratif T661 qui se lit clairement et suit la structure en trois volets de l’ARC. Voici un court fragment, légèrement anonymisé :
L’équipe a développé des algorithmes d’apprentissage automatique avancés pour résoudre des goulets d’étranglement de performance dans le pipeline de données. Nous avons examiné plusieurs approches de pointe et évalué leur efficacité par rapport aux solutions existantes. L’investigation systématique a impliqué une expérimentation itérative avec des architectures novatrices, et le projet a réalisé un avancement technologique dans le domaine du traitement distribué des données.
La prose est fluide. Elle suit la bonne structure. Un directeur financier qui la lit à froid n’aurait pas de raison évidente de la signaler. Un conseiller en recherche et technologie de l’ARC en aurait plusieurs.
L’expression « algorithmes d’apprentissage automatique avancés » est générique : elle ne correspond pas à un algorithme spécifique ni à un problème précis. « Approches de pointe » est générique : elle ne nomme pas les approches. « Architectures novatrices » est générique : le narratif ne décrit pas ce qui était innovant. « Avancement technologique dans le domaine du traitement distribué des données » est générique : il n’articule pas le manque de connaissances comblé ni la base de référence publiée que le travail a dépassée.
Quand l’évaluateur de l’ARC demande à l’entreprise de produire les artefacts source derrière « expérimentation itérative avec des architectures novatrices », l’entreprise a un problème. Le narratif a été produit à partir d’une invite. L’invite n’incluait pas de données source. L’équipe technique a des commits et des pull requests et des tickets, mais elle doit les trouver après que la question a été posée. Une partie du travail que le narratif décrit a bien eu lieu. Une partie ne s’est pas produite tout à fait comme la prose l’implique.
Exemple 2 : la capture en pratique
Une deuxième entreprise, de taille et de stack similaires, soumet la même réclamation via un outil d’IA basé sur la capture. L’outil lit directement l’historique git de l’entreprise, les tickets Jira et les messages Slack tagués. Il ne rédige pas un narratif à partir d’une invite. Il structure les preuves dans des catégories alignées sur l’ARC. Chaque élément capturé porte son artefact source, son auteur et sa date.
Le résultat pour le même projet pourrait ressembler à ceci :
Au T1 2026, l’équipe a examiné si un schéma de partitionnement hiérarchique personnalisé pouvait maintenir une latence de requête p95 inférieure à 150 ms sur le service d’analyse sous des lectures simultanées dépassant 12 000 requêtes par seconde. Les approches existantes (hachage cohérent selon Karger et al., partitionnement par plage selon la documentation Postgres, et le schéma de réplication multi-leader décrit dans le document d’architecture interne, Jira CHR-2189) étaient inadéquates pour le schéma d’accès. L’équipe a évalué quatre approches sur six semaines : une stratégie de promotion des clés chaudes (commits 4a7f2c1 à 8e1a4b3, PR #482), un cache à deux niveaux avec invalidation en écriture (commits c2d8f01 à 6b9e2c4, PR #496), un schéma de partitionnement personnalisé basé sur le clustering des schémas d’accès (commits 19c4d3a à 4e7f8a2, PR #507), et un hybride des deux (commits 7a3b9c1 à 2f6e0d8, PR #511). La quatrième approche a atteint une latence p95 de 142 ms à 13 400 RPS lors des tests de charge le 2026-02-14, documentée dans Jira CHR-2247. Les trois premières ont échoué.
La prose est plus dense. Chaque affirmation renvoie à un artefact source. L’incertitude technologique est articulée de manière précise. L’investigation systématique est articulée de manière précise : quatre approches, datées, avec les modes d’échec des trois premières documentés.
Quand l’évaluateur de l’ARC demande d’où provient l’affirmation « le cache à deux niveaux a produit des incohérences sous des écritures simultanées », la réponse est un seul clic qui atterrit sur le PR #496 avec les résultats de tests pertinents dans le ticket Jira lié. L’écran de filtrage ne signale pas le dossier. Le conseiller technique le lit sans recourir aux heuristiques d’échec de crédibilité.
Les deux exemples décrivent le même travail d’ingénierie sous-jacent. Le premier est de la génération. Le second est de la capture. Les deux ont pris un temps similaire à produire. Un seul fonctionne comme défense en audit.
Que recherchent réellement les évaluateurs de l’ARC?
Le Manuel de vérification des réclamations de l’ARC est accessible au public, et la séquence procédurale n’a pas changé dans sa substance depuis des années. Le conseiller en recherche et technologie examine le dossier selon cinq éléments dans l’ordre : une description claire du projet, l’incertitude technologique à l’étude, l’investigation systématique menée pour l’aborder, l’avancement technologique ou scientifique réalisé ou recherché, et la preuve du travail effectivement accompli.
Ce qui a changé, c’est l’étalonnage. En 2026, l’évaluateur attend de la spécificité à chaque étape. La section « incertitude technologique » doit articuler ce qui n’était pas connaissable à partir des méthodes existantes. La section « investigation systématique » doit décrire ce qui a été essayé, observé, modifié et conclu. La section « avancement technologique » doit identifier le manque de connaissances comblé et l’état de l’art que le travail a dépassé.
L’écran d’IA du côté de la vérification est étalonné aux mêmes attentes. Il ne vérifie pas littéralement si votre narratif a été rédigé par un modèle. Il vérifie les schémas que les outils basés sur la génération tendent à produire : faible spécificité, formulations génériques, liens manquants vers des sources, langage d’incertitude technologique sans manques de connaissances articulés.
Comment appliquer ce test à votre propre documentation?
Choisissez un projet du trimestre dernier. Demandez à votre outil ou consultant de produire le narratif T661 pour ce projet. Lisez le narratif. Choisissez ensuite un paragraphe au hasard et posez la question : « D’où dans notre historique git ou notre gestionnaire de tickets ce paragraphe provient-il? »
La bonne réponse est un seul clic qui atterrit sur l’artefact source. L’outil doit démontrer la traçabilité, pas la décrire. Si la réponse est « nous avons généré ceci à partir de la description du projet que nous avons fournie », l’outil est basé sur la génération. Si la réponse implique d’ouvrir la base de code manuellement pour trouver la preuve après coup, c’est de la reconstruction. Si la réponse est un hash de commit et une date, c’est de la capture.
Le test de lecture à froid est aussi utile. Demandez à votre responsable technique de lire le narratif sans contexte. Posez la question : est-ce que cela ressemble au travail que votre équipe a réellement fait, ou à du travail qui aurait pu être fait par n’importe qui dans le même secteur vertical? Le détail technique spécifique est le signal de la capture. Les formulations génériques sont le signal de la génération. Le test de lecture à froid prend moins de cinq minutes.
Quoi transmettre à votre directeur financier?
Si vous êtes un directeur technique qui envoie ceci à votre directeur financier avant une conversation de validation, voici les points pertinents.
La documentation IA basée sur la génération ne satisfait pas l’exigence de preuve contemporaine du programme d’approbation préalable aux réclamations de l’ARC. Le narratif est produit au moment de la déclaration, ce qui est exactement ce que « pas contemporain » signifie selon les termes de l’ARC. L’écran d’IA du côté de la vérification est étalonné contre les schémas que la génération produit. CPA Canada a déclaré officiellement que la responsabilité des déclarations assistées par IA incombe au déclarant, quelle que soit la façon dont l’IA a été utilisée.
La documentation IA basée sur la capture satisfait l’exigence. La preuve est la donnée source. Le narratif est structuré à partir des artefacts, pas généré à partir d’une invite. La provenance est intégrée dans chaque affirmation. En audit, la réponse à « d’où cela provient-il? » est un hash de commit, pas une description de l’invite.
La différence de coût entre les deux architectures est réelle mais secondaire. Une réclamation rejetée coûte plus qu’un outil plus coûteux. Le calcul sur une réclamation de 400 000 $ avec un rejet de 30 % donne un rappel de 120 000 $ avant les honoraires professionnels et les intérêts.
FAQ
Comment savoir si mon outil RS&DE actuel est basé sur la capture ou la génération?
Posez une seule question : d’où provient chaque affirmation technique dans notre T661? Si la réponse implique d’ouvrir la base de code pour trouver la preuve après coup, vous êtes en train de générer. Si la réponse est un hash de commit ou un identifiant de ticket, vous capturez.
Qu’est-ce que la « documentation contemporaine » selon l’ARC?
L’ARC définit la documentation contemporaine comme des dossiers créés pendant le travail lui-même, pas reconstitués au moment de la déclaration. Cela inclut les commits, les pull requests, les tickets du gestionnaire de tickets, les notes de conception et les résultats de tests datés de la période où le travail a été effectué.
La documentation RS&DE basée sur la capture est-elle plus coûteuse à produire?
Pas si l’on tient compte du risque d’audit. Un rejet de 30 % sur une réclamation de 400 000 $ représente 120 000 $ avant les honoraires professionnels et les intérêts. La plupart des outils basés sur la capture coûtent une fraction de ce montant par an. Le calcul favorise la capture pour toute entreprise avec une réclamation non négligeable.
Prêt à voir la documentation par capture sur votre propre dépôt? Réservez une démo de 25 minutes. Nous connecterons Lucius à un dépôt de démonstration et tracerons un paragraphe généré jusqu’au commit d’origine, devant vous.