L’IA agentique est une classe de systèmes d’intelligence artificielle capables de percevoir leur environnement, de prendre des décisions et d’agir de manière autonome pour atteindre un objectif. Contrairement à l’IA générative, qui produit du texte, des images ou du code sur demande, un système d’IA agentique utilise des outils, gère l’état entre les interactions et exécute des flux de travail en plusieurs étapes sans attendre l’intervention humaine à chaque étape. Un agent IA ne fait pas que générer. Il agit.
Cette distinction semble théorique jusqu’au moment où vous essayez d’en construire un. Générer une réponse est un simple appel de fonction. Construire un système qui lit un ticket de support, récupère les données du compte client depuis votre CRM, vérifie son niveau d’abonnement, rédige une réponse, applique une réduction si le client y a droit, met à jour le système de facturation et envoie l’e-mail, le tout sans intervention humaine, est un problème d’ingénierie fondamentalement différent. L’architecture est différente. Les modes d’échec sont différents. La stratégie de test est différente. La charge opérationnelle est différente.
La plupart des contenus sur l’IA agentique sont écrits par des personnes qui l’étudient de l’extérieur. Ce guide est écrit de l’intérieur, par une équipe qui déploie des systèmes d’agents en production dans les secteurs fintech, healthtech et SaaS entreprise. Ce qui suit, c’est ce que nous avons appris sur ce qu’est réellement l’IA agentique, comment elle fonctionne sous le capot, et ce qu’il faut pour construire des systèmes d’agents fiables à grande échelle.
En quoi l’IA agentique diffère de l’IA traditionnelle et de l’IA générative
Le terme “IA” couvre un large spectre, et les frontières entre les catégories sont floues. Mais les distinctions entre IA traditionnelle, IA générative et IA agentique comptent quand vous prenez des décisions d’architecture.
L’IA traditionnelle est basée sur des règles et déterministe. Un modèle de détection de fraude évalue les transactions selon un ensemble fixe de caractéristiques. Un moteur de recommandation classe les éléments par filtrage collaboratif. Ces systèmes font une chose bien, et ils la font de la même manière à chaque fois. Vous définissez les règles. Le système les suit.
L’IA générative crée de nouveaux contenus. Les grands modèles de langage (LLMs) comme GPT-4 et Claude génèrent du texte, du code et des analyses à partir d’une invite. Ils peuvent raisonner, résumer, traduire et rédiger. Mais un LLM standard n’a aucune capacité d’agir sur le monde. Demandez à ChatGPT de mettre à jour votre CRM, et il écrira une description de comment mettre à jour votre CRM. Il ne touchera pas la base de données.
L’IA agentique comble cet écart. Un agent enveloppe un LLM avec la capacité d’appeler des outils, de maintenir un état et d’exécuter des séquences d’actions vers un objectif défini. Le LLM devient un moteur de raisonnement à l’intérieur d’un système plus large qui peut observer, planifier, décider et agir.
Le passage du génératif à l’agentique n’est pas progressif. Il modifie le profil de risque, les exigences de test et la complexité opérationnelle de tout ce que vous construisez. Un chatbot qui donne une mauvaise réponse est agaçant. Un agent qui envoie le mauvais e-mail à 10 000 clients est un incident de production.
Pour une comparaison approfondie de ces deux paradigmes, y compris les compromis techniques spécifiques, consultez notre analyse complète : IA agentique vs. IA générative.
Les composants fondamentaux d’un système d’IA agentique
Chaque système d’agent en production que nous avons construit partage un ensemble commun de composants. Les détails d’implémentation varient selon le cas d’usage, mais l’architecture suit un modèle cohérent.

Moteur LLM
Le LLM est le moteur de raisonnement. Il interprète l’intention de l’utilisateur, décide quels outils appeler, traite les résultats et détermine les prochaines étapes. La plupart des systèmes en production utilisent aujourd’hui GPT-4, Claude, ou une combinaison de modèles routés par complexité de tâche.
Le choix du modèle compte plus que la plupart des équipes ne le réalisent. Un agent orienté client gérant des transactions financières nécessite un modèle avec un fort suivi des instructions et de faibles taux d’hallucination. Un agent interne qui résume des notes de réunion peut utiliser un modèle plus petit et moins coûteux. Nous exécutons généralement 2-3 modèles dans un seul système, routés par type de tâche. Le modèle coûteux gère les décisions à enjeux élevés. Le modèle rapide gère le formatage et l’extraction.
Appel d’outils
Les outils sont ce qui fait d’un agent un agent. Sans outils, vous avez un chatbot. Avec des outils, vous avez un système capable d’interroger des bases de données, d’appeler des API, de lire des fichiers, d’envoyer des messages, de mettre à jour des enregistrements et de déclencher des flux de travail en aval.
Un outil est simplement une fonction que le LLM peut invoquer. En pratique, cela signifie définir un schéma (ce que fait l’outil, quels paramètres il accepte, ce qu’il retourne) et le connecter à la boucle d’exécution de l’agent. Quand l’agent décide qu’il doit rechercher un enregistrement client, il appelle l’outil get_customer avec l’identifiant du client. L’outil s’exécute, retourne les données, et l’agent intègre le résultat dans sa prochaine étape de raisonnement.
L’ensemble d’outils définit la limite de capacité de l’agent. Un agent ayant accès à des requêtes en lecture seule est fondamentalement plus sûr qu’un agent pouvant écrire dans des tables de production. Concevoir la bonne surface d’outils, ce que l’agent peut et ne peut pas faire, est l’une des décisions d’architecture les plus importantes dans tout système d’agents.
Mémoire et gestion d’état
Les agents ont besoin de mémoire. La mémoire à court terme est le contexte de conversation : ce qui a été dit, quels outils ont été appelés, quelles données ont été récupérées dans cette session. La mémoire à long terme est la connaissance persistante : préférences des clients, interactions précédentes, patterns appris, documents de référence.
La mémoire à court terme est généralement gérée via la fenêtre de contexte du LLM. Le défi est les limites de contexte. GPT-4 Turbo vous offre 128K tokens. Claude vous offre 200K. Ça semble beaucoup jusqu’à ce que votre agent traite un contrat de 50 pages avec l’historique de conversation et les sorties d’outils. La gestion de la fenêtre de contexte, décider quoi garder, quoi résumer, quoi évincer, est un problème d’ingénierie actif dans chaque système d’agents.
La mémoire à long terme réside généralement dans une base de données vectorielle (Pinecone, Weaviate, pgvector) ou un magasin de connaissances structuré. L’agent récupère le contexte pertinent au moment de l’inférence via la recherche sémantique. C’est la “récupération” dans la génération augmentée par récupération (RAG), et bien la faire est la différence entre un agent qui se souvient de vos préférences et un agent qui vous pose les mêmes questions à chaque session.
Planification et raisonnement
Étant donné un objectif, l’agent doit déterminer les étapes à suivre. C’est là qu’interviennent le raisonnement en chaîne, la décomposition des tâches et le suivi des objectifs.
Les agents simples gèrent cela implicitement. Le LLM reçoit une invite comme “Traiter cette demande de remboursement” et détermine les étapes : rechercher la commande, vérifier la politique de remboursement, calculer le montant, émettre le remboursement, envoyer l’e-mail de confirmation. La planification se fait dans le processus de raisonnement du modèle.
Les agents complexes ont besoin d’une infrastructure de planification explicite. Un système multi-agents coordonnant un pipeline de données peut décomposer une tâche en sous-tâches, les assigner à des agents spécialisés, suivre la complétion, gérer les échecs et fusionner les résultats. Cela nécessite une couche d’orchestration en dehors du LLM, quelque chose comme un DAG (graphe acyclique dirigé) de tâches avec des dépendances, des nouvelles tentatives et une gestion des délais.
L’écart entre “fonctionne en démo” et “fonctionne en production” se situe presque toujours dans la couche de planification. Les démos utilisent des flux simples et linéaires. Les systèmes de production rencontrent des cas limites, des échecs partiels, des entrées ambiguës et des contraintes conflictuelles. L’infrastructure de planification doit tout gérer.
Observation et boucles de rétroaction
Un agent efficace évalue ses propres sorties. Après avoir appelé un outil, il vérifie le résultat. L’API a-t-elle retourné une erreur ? Les données sont-elles dans le format attendu ? La réponse a-t-elle du sens dans le contexte ?
C’est le cycle observation-action. L’agent agit, observe le résultat et décide de continuer, de réessayer ou d’adopter une approche différente. Sans cette boucle, les agents échouent silencieusement. Ils envoient des e-mails avec des champs vides. Ils écrivent des données dans la mauvaise table. Ils rapportent avec confiance des résultats d’un appel API défaillant.
Construire des boucles d’observation fiables signifie instrumenter chaque appel d’outil avec une logique de validation. Si l’agent appelle une API de paiement et obtient une erreur 500, le système doit le capturer, décider de réessayer et signaler l’échec si les tentatives sont épuisées. C’est de l’ingénierie standard des systèmes distribués. La différence est que l’orchestrateur qui prend ces décisions est un modèle de langage, pas une machine à états.
Ce que font vraiment les agents IA en production
L’écart entre les agents de démo et les agents de production est énorme. Un agent de démo traite cinq exemples soigneusement sélectionnés. Un agent de production gère des milliers de requêtes par jour sur des données réelles et désordonnées.
Voici où les agents fonctionnent en production aujourd’hui, gérant du trafic réel et prenant de vraies décisions.
Opérations clients. Des agents qui trient les tickets de support, récupèrent le contexte du compte depuis plusieurs systèmes, rédigent des réponses et routent les problèmes complexes vers des spécialistes humains. Les meilleures implémentations résolvent 40-60% des tickets de niveau 1 sans intervention humaine.
Révision de code et flux de travail d’ingénierie. Des agents qui examinent les pull requests, vérifient les vulnérabilités de sécurité, valident la couverture des tests et signalent les problèmes architecturaux. Ils ne remplacent pas les ingénieurs seniors. Ils interceptent les problèmes évidents avant que les réviseurs humains n’y consacrent du temps.
Traitement de documents. Des agents qui ingèrent des contrats, des factures, des dépôts réglementaires et des dossiers médicaux. Ils extraient des données structurées, signalent des anomalies et routent les documents dans les flux d’approbation. Un seul agent traitant des demandes d’assurance peut gérer l’équivalent du travail de 3 à 4 processeurs humains.
Automatisation des ventes. Des agents qui recherchent des prospects via des données publiques, enrichissent les enregistrements CRM, personnalisent les séquences de prospection et qualifient les leads selon les signaux d’engagement. Le gain opérationnel pour une équipe commerciale est significatif quand l’agent gère la recherche et la saisie de données qui consommaient 30% du temps d’un représentant.
Systèmes de connaissance interne. Des agents qui répondent aux questions des employés en cherchant dans la documentation, l’historique Slack, les pages Confluence et les dépôts de code. Ils résolvent le problème “qui sait où est ce document” qui afflige toute entreprise de plus de 50 personnes.
Pour des exemples détaillés de systèmes d’agents en production dans différents secteurs, consultez Exemples d’agents IA dans des produits réels.
Comment construire des systèmes d’IA agentique
Construire un système d’agents en production implique un ensemble de décisions que la plupart des équipes sous-estiment jusqu’à ce qu’elles soient profondément dans l’implémentation.
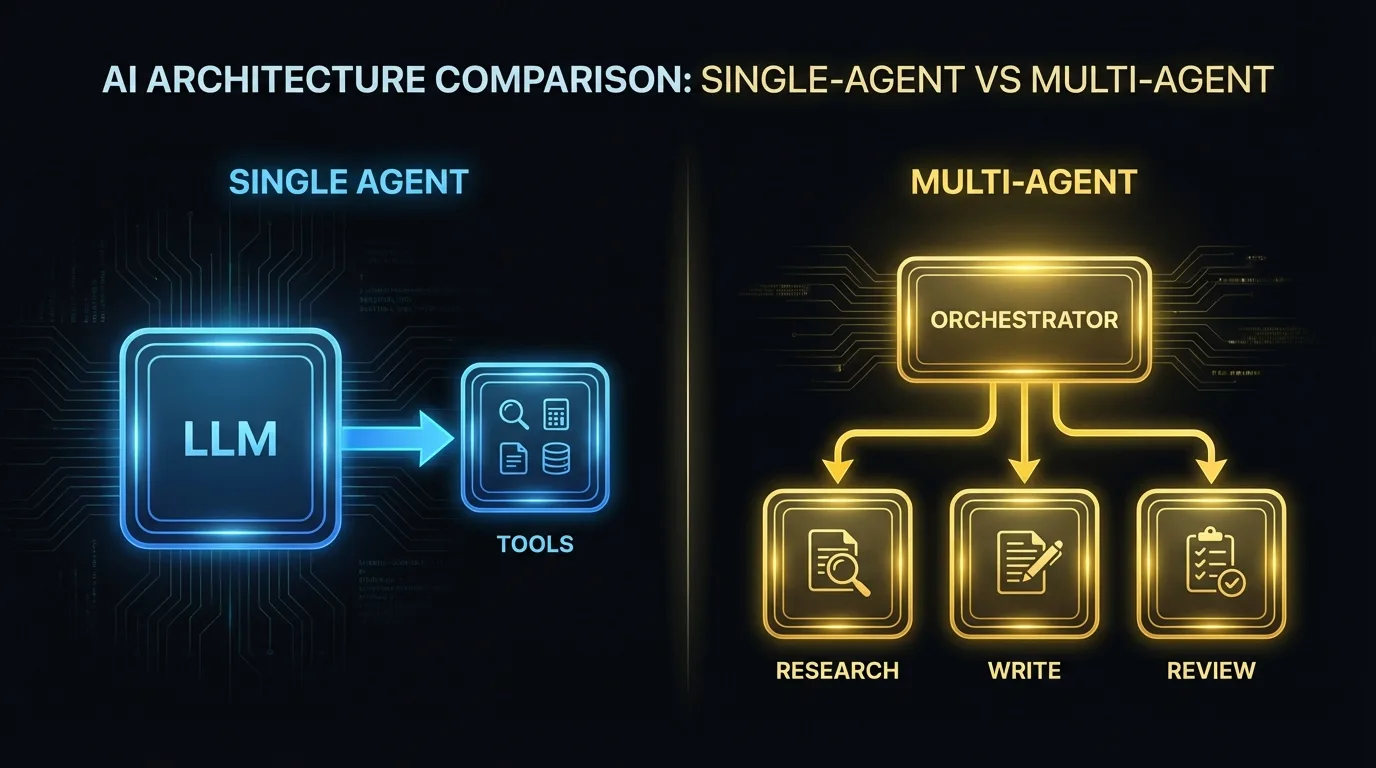
Architecture : agent unique vs. multi-agents
La première décision est de savoir si votre système nécessite un ou plusieurs agents.
Un agent unique avec un ensemble d’outils bien défini fonctionne pour des flux de travail délimités et linéaires. Traiter un remboursement. Résumer un document. Trier un ticket. Un LLM, un ensemble d’outils, une boucle d’exécution.
Les systèmes multi-agents sont nécessaires quand le flux de travail implique des capacités distinctes ou quand les tâches doivent s’exécuter en parallèle. Un pipeline de contenu peut avoir un agent qui fait des recherches, un autre qui rédige le brouillon, un autre qui vérifie les faits avec les documents sources, et un orchestrateur qui gère le flux. Chaque agent est spécialisé, avec ses propres outils et son propre prompt système.
Le compromis est la complexité. Les systèmes multi-agents sont plus difficiles à déboguer, à tester et à analyser. Commencez avec un seul agent. Divisez en plusieurs agents seulement quand vous atteignez des limites de capacité claires.
Infrastructure d’évaluation
C’est là où la plupart des équipes sous-investissent, et ça les rattrape rapidement.
Les logiciels déterministes ont des tests déterministes. Vous appelez une fonction avec l’entrée X, vous attendez la sortie Y. Les systèmes d’agents sont non déterministes. La même entrée peut produire des sorties différentes selon la température du modèle, le contenu de la fenêtre de contexte et le timing des réponses d’outils.
Une évaluation efficace des agents nécessite plusieurs couches. Des tests unitaires pour les outils individuels. Des tests d’intégration pour les chaînes d’outils. Des ensembles de données d’évaluation avec des comportements attendus (pas des sorties exactes). Des pipelines de révision humaine pour les cas limites. Et une surveillance continue en production pour détecter la dérive dans le temps.
Nous construisons généralement des harnais d’évaluation qui exécutent des centaines de cas de test contre l’agent à chaque déploiement. Chaque cas de test définit un scénario d’entrée, les appels d’outils attendus et les critères de sortie acceptables. Le système n’a pas besoin de produire des sorties identiques. Il doit prendre les bonnes actions et rester dans les limites comportementales.
Sécurité et garde-fous
Les agents agissent sur le monde. Cela signifie que chaque action a des conséquences, et certaines de ces conséquences sont irréversibles.
Le système de garde-fous définit ce que l’agent est autorisé à faire, dans quelles conditions, et quand il doit escalader vers un humain. C’est la conception avec l’humain dans la boucle. Chaque action n’a pas besoin d’approbation humaine. Mais les actions destructives (supprimer des données, envoyer des communications externes, modifier la facturation) devraient l’exiger jusqu’à ce que le système ait prouvé sa fiabilité.
Les garde-fous pratiques incluent : des listes d’outils autorisés (l’agent ne peut appeler que des outils approuvés), la validation des paramètres (l’agent peut émettre des remboursements, mais pas au-dessus de 500 $), la limitation du débit (l’agent peut envoyer des e-mails, mais pas plus de 100 par heure), et les mécanismes de retour en arrière (chaque action d’écriture enregistre suffisamment d’état pour être annulée).
Modélisation des coûts
Les coûts de tokens sont la réalité opérationnelle des systèmes d’agents. Chaque appel LLM a un coût. Chaque appel d’outil qui implique un LLM (pour l’analyse des sorties, pour la prise de décision) s’ajoute à ce coût. Un flux de travail d’agent complexe qui fait 15 appels LLM pour traiter une seule requête peut coûter entre 0,10 $ et 0,50 $ par exécution.
À 10 000 requêtes par jour, c’est entre 1 000 $ et 5 000 $ par jour en coûts d’inférence seuls. La modélisation des coûts doit se faire avant le déploiement, pas après avoir reçu la facture.
Stratégies de gestion des coûts : routage de modèles (utiliser des modèles bon marché pour les tâches simples, des modèles coûteux pour les complexes), mise en cache (ne pas retraiter des entrées identiques), budgets de tokens (fixer des limites strictes sur la consommation de tokens par requête), et traitement par lots (agréger des tâches similaires pour réduire la surcharge par élément).
Déploiement et opérations
Les systèmes d’agents nécessitent la même discipline opérationnelle que tout service en production, plus une surveillance supplémentaire pour les modes d’échec spécifiques à l’IA.
Les déploiements canari sont essentiels. Déployez d’abord les changements d’agents à 5% du trafic. Surveillez les pics de taux d’erreur, les anomalies de coûts et la dérive comportementale. Élargissez progressivement.
L’observabilité signifie journaliser chaque décision que l’agent prend : ce qu’il a observé, ce qu’il a raisonné, quels outils il a appelés, quels résultats il a obtenus et ce qu’il a fait ensuite. Quand quelque chose tourne mal (et ça arrivera), vous avez besoin de la trace complète pour diagnostiquer le problème.
La dégradation gracieuse signifie que le système dispose d’un chemin de secours quand l’agent échoue. Si l’agent ne peut pas traiter un ticket de support, il le route vers une file humaine au lieu de le supprimer. Si le LLM est indisponible, le système sert des réponses mises en cache ou des alternatives statiques plutôt que de retourner des erreurs.
Pour un cadre détaillé sur la construction de systèmes d’agents personnalisés, y compris la décision de construire vs. utiliser un framework, consultez Comment créer des agents IA personnalisés.
Les risques et les limites
L’IA agentique est puissante. Elle introduit aussi des modes d’échec qui n’existent pas dans les logiciels traditionnels ou les applications LLM simples. Les ignorer vous coûtera cher.
Erreurs en cascade
Un agent qui exécute un flux de travail en 5 étapes avec 95% de précision par étape délivre le résultat final correct seulement 77% du temps (0,95^5 = 0,774). À 10 étapes, vous tombez à 60%. À 20 étapes, 36%.
C’est le problème mathématique fondamental des systèmes autonomes. Chaque étape où l’agent peut prendre une mauvaise décision multiplie la probabilité d’un résultat final incorrect. Plus le flux est long, plus votre validation par étape doit être agressive.

Actions autonomes avec de vraies conséquences
Quand un agent envoie un e-mail, il est envoyé. Quand il met à jour un enregistrement de base de données, l’enregistrement est modifié. Quand il émet un remboursement, l’argent bouge. Il n’y a pas de bouton “annuler” pour la plupart des actions réelles.
C’est pourquoi l’architecture de garde-fous est si importante. Le coût d’un agent qui envoie un mauvais e-mail à un seul client est gérable. Le coût d’un agent qui envoie le mauvais e-mail à toute votre base clients est une crise. La différence entre ces deux scénarios, c’est l’infrastructure de limitation de débit et de délimitation de portée que vous construisez autour de l’agent.
Imprévisibilité des coûts
Les coûts d’inférence LLM sont variables. Un agent gérant une requête simple peut faire 3 appels d’outils et coûter 0,02 $. Le même agent gérant un cas limite peut faire 30 appels d’outils, en réessayer 5, et coûter 2,00 $. À grande échelle, cette variance crée des défis budgétaires pour lesquels la plupart des équipes ne sont pas préparées.
La solution est architecturale : budgets de tokens, disjoncteurs qui tuent les exécutions incontrôlées, et tableaux de bord de surveillance qui alertent sur les anomalies de coûts avant qu’elles ne deviennent des lignes sur la facture mensuelle.
Risque d’hallucination amplifié par l’action
Les LLMs hallucinent. C’est une limitation connue. Quand le LLM génère juste du texte, une hallucination produit une mauvaise réponse. Quand le LLM contrôle un agent qui agit sur son raisonnement, une hallucination produit une mauvaise action.
Un agent qui hallucine un numéro de compte client et interroge ensuite la base de données avec ce numéro récupérera les données du mauvais client. S’il traite ensuite un remboursement basé sur ces données, vous avez remboursé la mauvaise personne. L’hallucination n’a pas juste produit du mauvais texte. Elle a causé une erreur financière.
Atténuer ce risque nécessite une validation à chaque étape. Ne faites pas confiance au raisonnement interne de l’agent. Vérifiez les entrées d’outils par rapport aux schémas connus. Vérifiez les sorties d’outils par rapport aux formats attendus. Traitez le LLM comme un composant non fiable dans un système plus large.
Le problème d’évaluation
Tester les systèmes d’agents est plus difficile que tester des logiciels déterministes parce que les sorties sont non déterministes et l’espace d’états est combinatoire. Un agent avec 10 outils, chacun avec 5 entrées possibles, a 50 possibilités d’action distinctes à chaque étape d’un flux. Un flux de 5 étapes a 312 millions de chemins possibles.
Vous ne pouvez pas tous les tester. Vous testez les chemins qui comptent le plus (trafic élevé, risque élevé, haute valeur) et vous construisez une surveillance pour détecter les comportements inattendus en production. C’est une philosophie de test différente de celle à laquelle la plupart des équipes d’ingénierie sont habituées, et s’y adapter prend du temps.
Où va l’IA agentique
Le domaine évolue vite, mais quelques trajectoires sont claires d’après ce qui est déjà construit et déployé.
Coordination multi-agents
Les systèmes les plus sophistiqués en production aujourd’hui utilisent plusieurs agents spécialisés coordonnés via une couche d’orchestration. Un agent gère la recherche. Un autre gère la rédaction. Un autre gère les contrôles qualité. Un agent superviseur gère le flux, route les tâches et gère les échecs.
Ce pattern deviendra l’architecture par défaut pour les flux de travail complexes. Les systèmes mono-agent géreront les tâches délimitées. Les systèmes multi-agents géreront les processus métier de bout en bout. La couche d’orchestration, comment les agents communiquent, partagent l’état et résolvent les conflits, deviendra un composant d’infrastructure critique.
Les agents comme membres d’équipe
Les équipes d’ingénierie logicielle utilisent déjà des agents IA pour la révision de code, la génération de tests et la documentation. La prochaine étape est des agents qui participent au cycle de développement comme membres d’équipe à part entière. Des agents qui surveillent les systèmes de production, diagnostiquent les incidents, proposent des correctifs et ouvrent des pull requests. Des agents qui révisent les décisions architecturales par rapport aux conventions de l’équipe. Des agents qui intègrent les nouveaux ingénieurs en les guidant à travers la base de code.
Dans 18 mois, chaque équipe d’ingénierie au-delà d’une certaine taille aura des systèmes d’agents intégrés dans son flux de travail. La question n’est pas de savoir s’il faut les adopter. C’est comment les intégrer de manière à améliorer réellement la productivité de l’équipe plutôt que de créer une nouvelle catégorie de charge de maintenance.
Agents spécialisés plutôt que généralistes
L’agent “tout faire” est une démo convaincante et un mauvais produit. Les agents généralistes répartissent trop leurs capacités. Ils sont médiocres en tout et excellents en rien.
La trajectoire est vers des agents spécialisés qui vont en profondeur sur un problème. Un agent qui gère le traitement des demandes d’assurance. Un agent qui gère la documentation des essais cliniques. Un agent qui gère votre flux de comptes créditeurs. Ces agents connaissent les règles du domaine, les cas limites et les exigences réglementaires. Ils portent des ensembles d’outils et des critères d’évaluation spécialisés.
Construire des agents spécialisés nécessite une expertise métier, pas seulement des compétences en ingénierie IA. Les équipes qui réussiront combineront une connaissance approfondie d’un secteur spécifique avec de solides fondamentaux en construction d’agents.
Autonomie supervisée, pas autonomie totale
L’avenir proche de l’IA agentique n’est pas des systèmes entièrement autonomes qui remplacent les travailleurs humains. C’est l’autonomie supervisée : des agents qui gèrent les 80% routiniers d’un flux de travail pendant que les humains gèrent les 20% complexes.
Ce modèle fonctionne parce qu’il joue sur les forces des deux parties. Les agents sont rapides, cohérents et infatigables pour la reconnaissance de patterns et l’exécution. Les humains sont bons pour le jugement, le contexte et la gestion des situations qui sortent de la distribution d’entraînement. Les meilleurs systèmes d’agents rendent l’opérateur humain plus efficace, pas redondant.
L’autonomie totale viendra éventuellement pour des domaines spécifiques bien délimités. Mais pour les 3 à 5 prochaines années, la valeur est dans l’autonomie supervisée. Les entreprises qui conçoivent leurs systèmes d’agents avec la supervision humaine intégrée dans l’architecture déploieront plus vite et échoueront moins catastrophiquement que celles qui courent après l’automatisation totale.
L’opportunité
L’IA agentique change comment les logiciels sont construits et opérés. Pas de la façon “tout sera différent” que les cycles de hype promettent. D’une façon spécifique et mesurable : les tâches qui nécessitaient auparavant qu’un humain observe, décide et agisse peuvent maintenant être gérées par un système qui fait la même chose à la vitesse et à l’échelle d’une machine.
Les entreprises qui comprennent comment construire des systèmes d’agents fiables, avec une évaluation appropriée, des garde-fous et une supervision humaine, auront un avantage structurel. Elles automatiseront des flux de travail que leurs concurrents gèrent encore avec des personnes. Elles livreront des fonctionnalités qui seraient impossibles sans composants IA autonomes. Elles opéreront avec une structure de coûts que les processus manuels ne peuvent pas égaler.
L’écart entre les entreprises qui construisent bien des agents et celles qui ne le font pas va s’élargir rapidement. Les modèles sous-jacents se banalisent. Le différenciateur est l’ingénierie : la conception des outils, l’infrastructure d’évaluation, l’architecture de sécurité, la discipline opérationnelle.
Si votre équipe intègre l’IA dans un produit existant et a besoin d’un soutien en ingénierie pour mettre des systèmes d’agents en production de manière fiable, parlons-en.