Most generative AI projects fail the same way.
Not from bad engineering. Not from picking the wrong model. They fail because the team made a series of decisions in the first two weeks that locked them into a path that doesn’t work. By the time the problems surface, the codebase is six months old and nobody wants to rewrite the core architecture.
We’ve worked on generative AI products across fintech, healthtech, and enterprise SaaS. The failure patterns repeat with uncomfortable consistency. Different industries, different team sizes, different budgets. Same mistakes.
Here are the ones that keep showing up.
1. Starting with the model instead of the problem
The most common first step in a generative AI project: someone picks GPT-4o or Claude, gets an API key, and starts building a demo. The demo looks great. Leadership gets excited. Now the team has to figure out what problem they’re actually solving.
This is backwards.
The model is an implementation detail. The problem defines the architecture. A document summarization feature has completely different requirements from a conversational support agent. One needs high throughput and batch processing. The other needs sub-second latency and session management. Picking the model first means you’ve already constrained your architecture before you understand the constraints that actually matter.
The teams that ship successfully start with a specific workflow, a specific user, and a specific outcome. They define what “good” looks like in concrete terms before writing a single line of inference code. Then the model choice becomes obvious, because the requirements tell you what you need.
2. No evaluation infrastructure
This is the one that kills projects silently.
Without an evaluation suite, you can’t measure the quality of your outputs. You can’t compare prompts. You can’t regression-test after a model update. You can’t quantify whether your retrieval pipeline is actually helping. You’re shipping changes based on vibes.
Building eval infrastructure isn’t glamorous work. It means creating test datasets with known-good answers, building scoring rubrics (automated and human), and running evaluations on every change. Most teams skip this because the first version “works fine” in manual testing.
Then the model provider releases a new version. Or someone tweaks a system prompt. Or the retrieval context changes. Output quality degrades, but nobody notices for weeks because there’s no automated signal. By the time a customer complains, the damage is already done.
The eval suite should exist before the first production deployment. Not after. Treat it like your test suite for traditional software: if it doesn’t exist, the system isn’t production-ready.
3. Treating prompts as the product
Prompt engineering is a starting point. It’s a useful skill for prototyping and experimentation. It’s not an architecture.
A production generative AI system needs retrieval pipelines, output validation, guardrails for off-topic or harmful responses, fallback behavior when the model fails, caching strategies, and structured output parsing. The prompt is maybe 10% of the system. Teams that invest all their effort into crafting the perfect prompt and neglect everything around it end up with a system that works in demos and breaks in production.
The gap between “it works in the playground” and “it works at scale with real users” is where most of the engineering lives. That gap includes handling edge cases the model gets wrong, managing context windows as conversations grow, and building the observability layer that tells you what’s happening in production.
If your entire generative AI development effort lives inside prompt templates, you haven’t built a product. You’ve built a wrapper.
4. Underestimating latency
Users will not wait 8 seconds for a response. They won’t wait 5 seconds. In most product contexts, anything over 2 seconds feels broken.
This becomes a real problem with multi-step chains. If your architecture routes a user query through a classification step (500ms), then retrieval (300ms), then generation (2s), then output validation (400ms), you’re already at 3.2 seconds. Add network overhead and you’re pushing 4 seconds. Multiply that by the number of chain steps in a complex agent workflow.
Latency compounds. Every additional step adds time that users feel.
The fix isn’t just faster models. It’s architectural. Stream responses so the user sees tokens appearing immediately. Run independent steps in parallel instead of sequentially. Cache aggressively for repeated queries. Pre-compute where possible. Design the UX around perceived speed, not just actual speed.
Some of the best generative AI products feel fast not because the model is fast, but because the team designed every interaction to minimize perceived wait time. That’s an engineering and design problem, not a model problem.
5. Ignoring cost modeling until production
In development, you’re making maybe 100 API calls a day. At $0.01 per request, that’s a dollar. Nobody thinks about cost.
Then you launch. Suddenly you’re processing 10,000 requests a day. Your average request uses 4,000 input tokens and 1,000 output tokens. With a frontier model, you’re looking at $0.04-0.08 per request. That’s $400-800 per day. $12,000-24,000 per month. For a single feature.
And that’s the baseline. Add retrieval-augmented generation with large context windows and your costs double or triple. Add multi-step agent workflows where a single user action triggers 4-5 model calls and you’re at $0.20-0.30 per user interaction.
The teams that handle this well do the token math early. They model out per-request costs at production scale during the design phase. They make deliberate decisions about where to use frontier models and where a smaller, cheaper model performs well enough. They build cost monitoring into their observability stack from day one, not as an afterthought when the monthly invoice arrives.
A generative AI development company that doesn’t talk about cost modeling in the first week isn’t thinking about production.

6. Hiring a “Head of AI” before understanding the problem
The pattern: a company decides generative AI is strategic. They hire a senior “Head of AI” or “VP of AI” to lead the effort. That person spends 3-4 months building a strategy deck, evaluating vendors, and assembling a team. Six months in, nothing has shipped.
This isn’t a knock on AI leaders. The problem is sequencing. Title-based hiring before problem-based scoping means you’ve committed to an organizational structure before you know what you’re building. The Head of AI might be brilliant at ML infrastructure but your problem needs a product engineer who understands LLM application architecture. Or vice versa.
The companies that move fastest start with a specific problem and a small team that can ship something in weeks, not months. They figure out what expertise they actually need by building, not by planning. The leadership hire comes after you understand the shape of the work, not before.
If you need AI expertise embedded in your team to figure out the right approach, bring in experienced builders first. Strategy emerges from building. Not the other way around.
7. Building a chatbot when you need a workflow
The default UI for generative AI is a chat interface. It’s the path of least resistance. Slap a text input at the bottom, stream the response, and call it a product.
But most business problems don’t map to conversations. A compliance review workflow needs structured inputs, defined review stages, and audit trails. An underwriting process needs form fields, decision trees, and human approval gates. A content generation pipeline needs templates, brand rules, and editorial review.
Forcing these workflows into a chat interface creates a worse user experience, not a better one. Users have to type instructions instead of clicking through a guided process. They have to remember what to ask for instead of following a structured flow. Error handling becomes “ask again in a different way.”
The best generative AI products look nothing like ChatGPT. They look like purpose-built tools where the AI is invisible, doing its work behind structured interfaces that guide users through the process. The AI handles the hard cognitive work. The UI handles the human workflow around it.
Chat is sometimes the right answer. Customer support, open-ended research, coding assistants. For most enterprise use cases, it’s the lazy answer.
8. No human-in-the-loop from day one
Every generative AI system gets things wrong. Models hallucinate. They misinterpret ambiguous inputs. They generate outputs that are technically correct but contextually inappropriate. This isn’t a bug that gets fixed with better prompts. It’s a fundamental property of probabilistic systems.
The mistake isn’t expecting the model to be imperfect. The mistake is not designing for it.
Systems that can’t escalate to a human when confidence is low will fail publicly. An AI agent that sends an incorrect response to a customer with no review step doesn’t just create a bad experience. It creates a trust problem that’s hard to recover from. One wrong answer seen by the wrong person can kill adoption of the entire product.
Human-in-the-loop isn’t a phase you add later when the system is “mature enough.” It’s an architectural decision that shapes how you build the system. It determines your queue design, your notification logic, your latency budgets for different confidence levels, and your UX for the review interface. Bolting it on after launch means reworking half the system.
The practical implementation varies. High-confidence outputs can go straight through. Medium-confidence outputs get flagged for async review. Low-confidence outputs block until a human approves. The thresholds and routing logic become some of the most valuable IP in the system, because they define the boundary between automation and human judgment for your specific domain.
Teams that skip this step tend to compensate by making the model overly conservative, which defeats the purpose. Or they launch without guardrails and deal with the fallout. Neither approach works at scale.
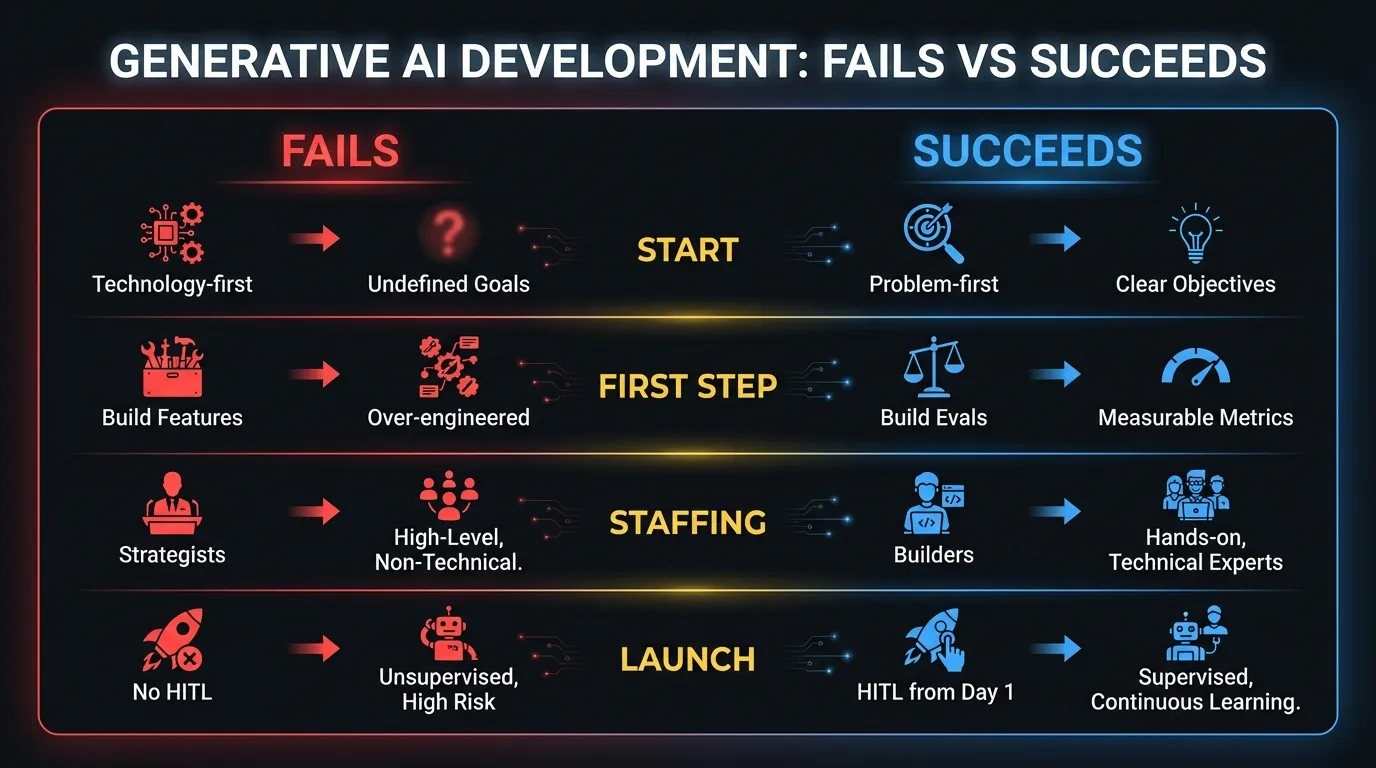
What good looks like
The companies that ship generative AI products successfully share a few traits.
They start with a narrowly scoped problem and a clear definition of success. Not “add AI to the product” but “reduce the time to generate a compliance report from 4 hours to 20 minutes, with 95% accuracy on regulatory citations.” Specificity forces good architecture decisions.
They build evaluation infrastructure before they build features. They know how to measure quality, so they can improve it systematically instead of guessing.
They treat cost and latency as first-class design constraints, not afterthoughts. Token budgets and response time targets live alongside functional requirements in the spec.
They staff with builders, not strategists. The first hire (or the first external team) ships something to real users within weeks. Strategy comes from what they learn, not from a pre-built playbook.
And they design for humans in the loop from day one. Every AI-generated output has a path to human review when confidence is low. Every agent can escalate. Every workflow includes the escape hatch that keeps the system trustworthy when the model gets it wrong.
None of this is theoretical. These are patterns from real codebases, real team structures, real product launches. The companies that avoid these mistakes aren’t necessarily smarter or better funded. They’ve just seen what failure looks like, either firsthand or through someone on the team who has.
Generative AI development is still new enough that most companies are learning by failing. The failures don’t have to be expensive. Most of them are avoidable if you know what to watch for and build with production realities in mind from week one, not week twenty.
Need help getting your first generative AI product to production without the usual wrong turns? Talk to us.